

Pyłek
Cel
Pyłek jest strukturalnym wzorcem projektowym pozwalającym zmieścić więcej obiektów w danej przestrzeni pamięci RAM poprzez współdzielenie części opisu ich stanów.

Problem
Aby rozerwać się nieco po pracy, postanawiasz stworzyć prostą grę komputerową: gracze poruszają się po mapie i strzelają do siebie. Chcesz zaimplementować realistyczny system cząstek i uczynić z niego wyróżniającą się zaletę gry. Niech wielkie ilości kul, rakiet i odłamków fruwają po całej mapie, dostarczając ekscytującej rozrywki.
Ukończywszy pracę, wykonujesz ostatni commit, kompilujesz grę i wysyłasz znajomemu na próbę. Chociaż gra chodzi płynnie na twoim komputerze, kolega nie może długo pograć. Po paru minutach gra się wiesza. Po wielogodzinnym poszukiwaniu przyczyn w dziennikach debugowych, zauważasz, że grze zabrakło pamięci RAM. Okazało się bowiem, że komputer kolegi jest słabszy niż twój i dlatego problem objawił się u niego tak szybko.
Źródłem problemu był system cząstek. Każda cząstka, jak kula, rakieta czy odłamek, reprezentowany był jako osobny obiekt zawierający mnóstwo danych. W którymś momencie, w czasie renderowania strzelaniny, nowo utworzone cząstki nie mieściły się w pamięci operacyjnej i gra kończyła działanie.
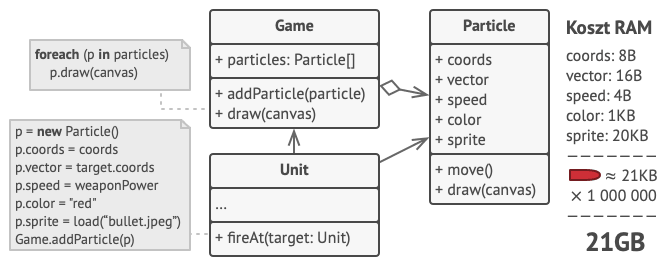
Rozwiązanie
Przy dokładniejszej inspekcji klasy Cząstka zauważamy, że kolor i sprite każdej cząstki zużywają znacznie więcej pamięci, niż inne pola obiektu. Co gorsza, te dwa pola przechowują niemal identyczne dane we wszystkich cząstkach. Na przykład — wszystkie kule mają tę samą barwę i sprite.
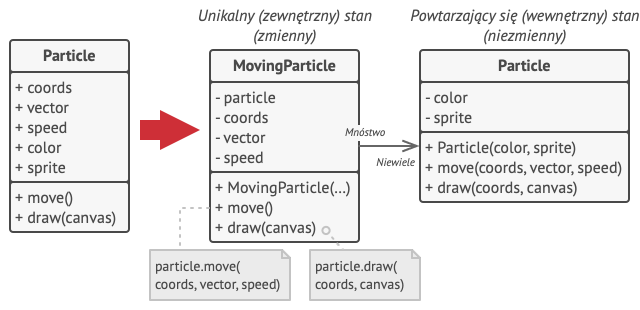
Inne elementy opisujące stan cząstki, jak współrzędne, wektor ruchu i prędkość są unikalne dla każdej z nich. Bo przecież te wartości ulegają ciągłej zmianie. Dane te reprezentują wciąż zmieniający się kontekst, w jakim cząstka się znajduje, zaś kolor i sprite pozostają jednakowe dla każdej z nich.
Dane niezmienne, opisujące obiekt, nazywa się stanem wewnętrznym. Opisany jest on w każdym z obiektów, zaś inne obiekty mają do niego tylko prawo odczytu. Reszta stanu obiektu, często zmienianym “z zewnątrz” przez inne obiekty, zwana jest stanem zewnętrznym.
Wzorzec Pyłek proponuje rezygnację z przechowywania stanu zewnętrznego w obiekcie. Zamiast tego należy przekazywać ten stan konkretnym metodom które go potrzebują. Tylko stan wewnętrzny powinien pozostać zapisany w obrębie obiektu, pozwalając na użycie go ponownie w innych kontekstach. Dzięki temu potrzebujemy mniej tych obiektów, ponieważ różnią się tylko pod względem wewnętrznego stanu, którego możliwych kombinacji jest znacznie mniej.
Wróćmy do naszej gry. Zakładając, że wyekstrahowaliśmy stan zewnętrzny z naszej klasy-cząstki, wystarczą zaledwie 3 obiekty, aby reprezentować wszystkie cząstki w grze: kulę, rakietę i odłamek. Jak zapewne już się domyślasz, obiekt przechowujący tylko stan wewnętrzny nazywa się Pyłkiem.
Przechowywanie danych zewnętrznych
Dokąd przenieść zewnętrzny stan? Jakaś klasa powinna go przechowywać, prawda? W większości przypadków, przenosi się go do obiektu kontenerowego, który agreguje obiekty zanim zastosujemy wzorzec.
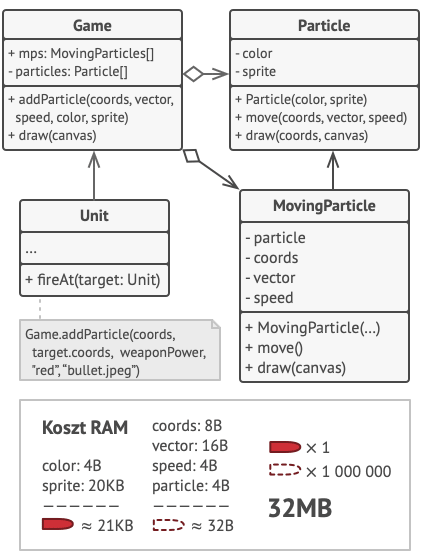
W naszym przypadku to główny obiekt Gra przechowuje wszystkie cząstki w polu cząstki. By przenieść zewnętrzne stany do tej klasy, musisz stworzyć wiele pól tablicowych do przechowywania współrzędnych, wektorów i prędkości każdej cząstki. Ale to nie wszystko — potrzebujesz jeszcze jednej tablicy w celu przechowania referencji do konkretnego pyłku reprezentującego cząstkę. Te dwie tablice muszą być zsynchronizowane, aby można było pobrać wszystkie dane cząstki stosując ten sam indeks.
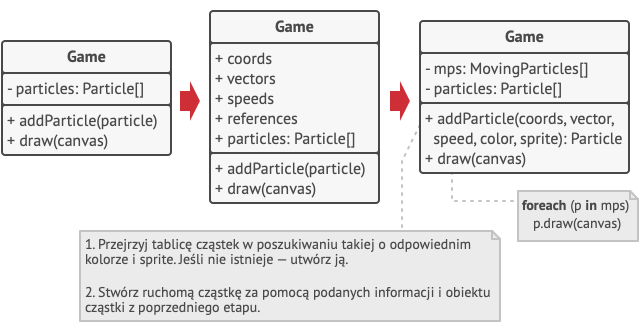
Bardziej eleganckim rozwiązaniem jest utworzenie osobnej klasy kontekstowej która przechowa zewnętrzny stan wraz z odniesieniem do obiektu pyłek. W takiej sytuacji potrzebna jest tylko jedna tablica w klasie kontenerowej.
Ale chwileczkę! Czy czasem nie będzie nam potrzebne tyle takich obiektów kontekstowych, ile mieliśmy na samym początku? W zasadzie tak, ale te obiekty są dużo mniejsze niż wcześniej. Pola zajmujące najwięcej pamięci przeniesiono do kilku obiektów pyłków. Teraz tysiąc małych obiektów kontekstowych może wykorzystać ponownie pojedynczy, duży obiekt pyłek, zamiast przechowywać tysiąc kopii ich danych.
Pyłek a niezmienność
Skoro ten sam obiekt pyłek może być wykorzystany w różnych kontekstach, musisz się upewnić, że jego stan nie może być zmieniony. Pyłek powinien inicjalizować swój stan tylko jednorazowo, za pośrednictwem parametrów konstruktora. Nie powinien eksponować innym obiektom żadnych setterów ani pól publicznych.
Fabryka pyłków
Stworzenie metody wytwórczej zarządzającej pulą istniejących obiektów pyłków daje nam wygodniejszy dostęp do różnych cząstek. Metoda przyjmuje pożądany przez klienta opis stanu wewnętrznego, poszukuje istniejącego obiektu o takim stanie i go zwraca. Jeśli go nie znajdzie — tworzy nowy i dodaje go do puli.
Istnieje wiele miejsc, gdzie można umieścić taką metodę. Najbardziej oczywistym jest kontener pyłków. Innym sposobem jest stworzenie nowej klasy fabrycznej. Można też uczynić metodę wytwórczą statyczną i umieścić ją w faktycznej klasie pyłek.
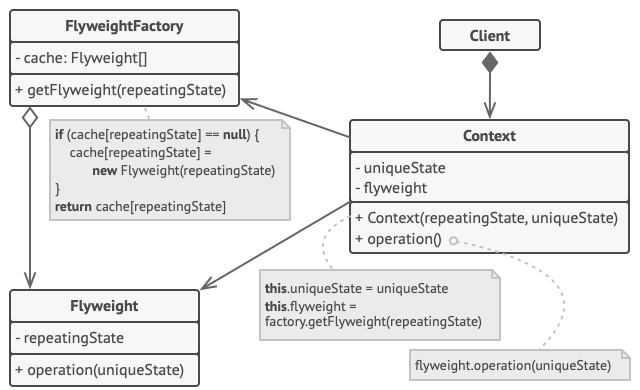
Struktura
-
Wzorzec Pyłek jest jedynie optymalizacją. Przed zastosowaniem go, upewnij się, że twój program ma potencjalny problem z wyczerpywaniem pamięci RAM wskutek istnienia jednocześnie wielkiej liczby podobnych obiektów. Odpowiedz sobie na pytanie, czy nie da się takiego problemu rozwiązać w inny sposób.
-
Klasa Pyłek zawiera tę porcję stanu pierwotnego obiektu, która może być współdzielona pomiędzy wieloma instancjami. Ten sam obiekt-pyłek może być wykorzystany w wielu kontekstach. Stan przechowywany w pyłku nazywa się wewnętrznym. Stan przekazywany metodom pyłka to dane zewnętrzne.
-
Klasa Kontekst zawiera opis zewnętrznego stanu, unikalny dla każdego z pierwotnych obiektów. Gdy kontekst skojarzy się z jednym z obiektów-pyłków, otrzymuje się reprezentację pełnego stanu pierwotnego obiektu.
-
Zazwyczaj obowiązki pierwotnego obiektu pozostają w klasie pyłek. W takim przypadku, w momencie wywołania metody pyłka, trzeba przekazać jej również odpowiednie elementy stanu zewnętrznego. Z drugiej strony, obowiązki można przenieść do klasy kontekstowej, która korzysta ze skojarzonego pyłku tylko jako obiektu danych.
-
Klient oblicza lub przechowuje zewnętrzny stan pyłków. Z punktu widzenia klienta, pyłek to obiekt szablonowy który może być skonfigurowany w trakcie działania programu poprzez przekazanie jakichś danych kontekstowych w charakterze parametrów jego metod.
-
Fabryka Pyłków zarządza pulą istniejących pyłków. Dzięki fabryce, klienci nie tworzą pyłków w sposób bezpośredni. Zamiast tego wywołują fabrykę, przekazują jej fragmenty danych o wewnętrznym stanie pożądanego pyłka. Fabryka przegląda poprzednio stworzone pyłki i albo zwraca odpowiedni, albo go tworzy.
Pseudokod
W poniższym przykładzie, wzorzec Pyłek pomaga zredukować zużycie pamięci podczas renderowania milionów obiektów-drzew na ekranie.
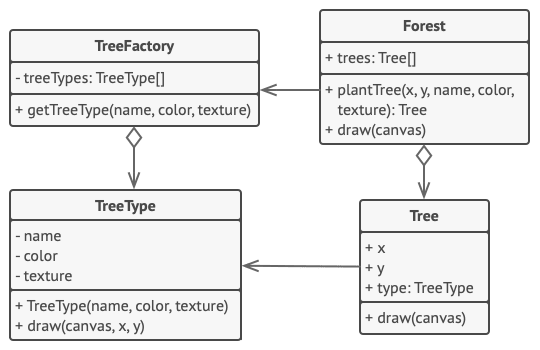
Działając według wzorca, ekstrahuje się powtarzający, wewnętrzny stan z głównej klasy Drzewo i przenosi do klasy pyłek o nazwie TypDrzewa.
Teraz, zamiast przechowywać te same dane w wielu obiektach, znajdują się one tylko w kilku obiektach-pyłkach, skojarzonych ze stosownymi obiektami Drzewo które służą za kontekst. Kod klienta tworzy nowe drzewa za pośrednictwem fabryki pyłków, która hermetyzuje złożoność poszukiwania odpowiedniego obiektu i jego ewentualnego ponownego użycia.
// Klasa pyłek zawiera część stanu drzewa. Pola te przechowują
// wartości które są unikalne dla każdego drzewa. Przykładowo
// nie znajdziemy tu współrzędnych drzewa, ale teksturę oraz
// wspólne barwy — owszem. Ponieważ te dane są zazwyczaj
// WIELKIE, zmarnowalibyśmy bardzo dużo pamięci operacyjnej,
// przechowując ich kopie w obrębie każdego z obiektów-drzew.
// Ekstrahujemy więc tekstury, barwy i inne powtarzające się
// dane do odrębnego obiektu. Wszystkie drzewa będą posiadać
// odniesienie do nowego obiektu.
class TreeType is
field name
field color
field texture
constructor TreeType(name, color, texture) { ... }
method draw(canvas, x, y) is
// 1. Utwórz mapę bitową o danym typie, kolorze i
// teksturze.
// 2. Narysuj mapę bitową na ekranie w punkcie o
// współrzędnych X i Y.
// Fabryka pyłków podejmuje decyzję o ponownym użyciu
// istniejącego obiektu-pyłka lub utworzeniu nowego.
class TreeFactory is
static field treeTypes: collection of tree types
static method getTreeType(name, color, texture) is
type = treeTypes.find(name, color, texture)
if (type == null)
type = new TreeType(name, color, texture)
treeTypes.add(type)
return type
// Obiekt-kontekst zawiera zewnętrzne elementy stanu drzewa.
// Aplikacja może stworzyć miliardy drzew, bo są one bardzo
// małe: opisują je dwie liczby całkowite oznaczające
// współrzędne i jedno pole przechowujące odniesienie do obiektu
// zawierającego opis stanu zewnętrznego.
class Tree is
field x,y
field type: TreeType
constructor Tree(x, y, type) { ... }
method draw(canvas) is
type.draw(canvas, this.x, this.y)
// Klasy Tree i Forest są klientami pyłku. Możesz je połączyć,
// jeśli nie zamierzasz dalej rozwijać klasy Tree.
class Forest is
field trees: collection of Trees
method plantTree(x, y, name, color, texture) is
type = TreeFactory.getTreeType(name, color, texture)
tree = new Tree(x, y, type)
trees.add(tree)
method draw(canvas) is
foreach (tree in trees) do
tree.draw(canvas)
Zastosowanie
Stosuj wzorzec Pyłek gdy twój program musi pracować z wielką ilością obiektów, które ledwo mieszczą się w dostępnej pamięci RAM.
Zyski z wprowadzenia tego wzorca zależą od tego jak i gdzie się go zastosuje. Największy pożytek uzyskuje się gdy:
- aplikacja musi tworzyć wielką ilość podobnych obiektów,
- powyższa sytuacja poważnie obciąża dostępną pamięć RAM urządzenia,
- obiekty zawierają wielokrotnie powtarzające się opisy stanów, dające się wyekstrahować i pozwoli się na współdzielenie ich pomiędzy wieloma obiektami.
Jak zaimplementować
-
Podziel na dwie części pola klasy z których powstanie pyłek:
- stan wewnętrzny: pola, które przechowają niezmienne dane, powtarzające się w wielu obiektach
- stan zewnętrzny: pola, które przechowają dane kontekstowe, unikalne dla każdego obiektu
-
Pozostaw pola reprezentujące wewnętrzny stan w klasie, ale upewnij się, że nie mogą być zmieniane. Powinny one przyjmować swój stan początkowy wyłącznie w konstruktorze.
-
Przejrzyj metody korzystające z pól zewnętrznego stanu. Dla każdego pola użytego w metodzie, dodaj nowy parametr i używaj go zamiast pola.
-
Opcjonalnie, utwórz klasę fabryczną służącą zarządzaniu pulą pyłków. Powinna ona poszukać istniejącego pyłka przed utworzeniem nowego. Gdy fabryka jest już gotowa, klienci powinni wnioskować o pyłki wyłącznie przez nią, przekazując opis stanu wewnętrznego żądanego obiektu.
-
Klient musi przechowywać lub wyliczać wartości opisujące stan zewnętrzny (kontekst), by mógł wywoływać metody obiektów-pyłków. Dla wygody, zewnętrzny stan wraz z polem odnoszącym się do pyłka można przenieść do osobnej klasy kontekstowej.
Zalety i wady
- Możesz zaoszczędzić mnóstwo pamięci RAM, o ile twój program tworzy mnóstwo podobnych obiektów.
- Może się zdarzyć, że oszczędność pamięci odbędzie się kosztem czasu procesora, gdyż część danych kontekstowych musi być wyliczana przy każdym wywołaniu metody pyłka.
- Kod staje się dużo bardziej skomplikowany. Nowi członkowie zespołu z pewnością będą się zastanawiać dlaczego stan czegoś został odseparowany.
Powiązania z innymi wzorcami
-
Węzły będące liśćmi drzewa Kompozytowego można zaimplementować jako Pyłki by zaoszczędzić nieco pamięci RAM.
-
Pyłek przedstawia sposób na stworzenie wielkiej liczby małych obiektów, zaś Fasada na stworzenie pojedynczego obiektu reprezentującego cały podsystem.
-
Pyłek mógłby przypominać Singleton, gdybyśmy zdołali zredukować wszystkie współdzielone stany obiektów do tylko jednego obiektu-pyłka. Ale są jeszcze dwie fundamentalne różnice między tymi wzorcami:
- Powinna istnieć tylko jedna instancja interfejsu Singleton, zaś instancji Pyłka będzie wiele, o różnym stanie wewnętrznym.
- Obiekt Singleton może być zmienny. Pyłki są zaś niezmienne.
Przykłady kodu
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
